«id =» main «> Поделиться
EDB Postgres Failover Manager, сокращенно EFM, — это инструмент для автоматического управления кластером базы данных Postgres. EFM обеспечивает инфраструктуру высокой доступности для EDB Advanced Server и версии сообщества PostgreSQL. Он позволяет отслеживать состояние ваших баз данных и репликации, генерировать предупреждения, повышать уровень до роли Мастера резервного узла, как в случае сбоя, так и вручную — в случае необходимости проведения профилактических работ на основном сервере кластер.
В статье обсуждается EDB Postgres Failover Manager версии 3.1.
Архитектура
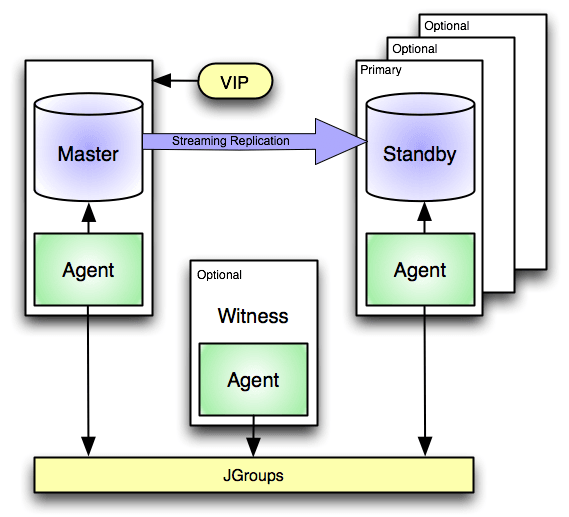
Минимальная конфигурация кластера, необходимая для правильной работы, предполагает использование двух серверов, работающих в режиме потоковой репликации: одного Master и одного Slave. Конечно, последних может быть и больше. Необязательный компонент установки — это сервер-свидетель, контролирующий работу кластера. Его можно опустить в упрощенных установках, но следует помнить, что это значительно увеличивает вероятность бесперебойной работы кластера в случае проблем с сетевым обменом данными.
Можно использовать виртуальный IP-адрес, назначенный главному серверу, который, конечно же, будет назначен новому продвинутому главному серверу. На каждом из серверов кластера, а также на следящем сервере, должна быть установлена и настроена служба агента, которая отвечает как за мониторинг активности кластера, так и за выполнение определенных действий в случае определенных событий. Действия, помимо тех, которые реализованы заранее, могут быть дополнены скриптами, вводимыми администратором.
Службы агента на всех узлах кластера взаимодействуют друг с другом с помощью программного обеспечения JGroups, которое устанавливается вместе со службой агента. Номера портов для связи между агентами настраиваются в файле конфигурации агента, поэтому не забудьте включить связь на выбранных портах на брандмауэре.

Если ни одна служба агента не может это видеть база данных, служба агента, установленная на главном узле, освобождает виртуальный IP-адрес, создает файл recovery.conf, а затем сообщает другим экземплярам службы агента о сбое основной базы данных. Службы агентов на других узлах пытаются восстановить соединение с базой данных Master, в случае успеха отправляется уведомление об этом факте.
Если подключение невозможно, службы агента подтверждают, что виртуальный адрес был освобожден, если нет, отправляется уведомление.
Если виртуальный IP-адрес освобожден, служба агента выполняет сценарий, определенный как «script.fence» на самом последнем узле (если он определен).
Затем, в зависимости от результата сценария, он продвигает базу Slave в Master и назначает виртуальный IP-адрес новому серверу Master. В случае результата сценария, отличного от успеха («0»), он завершает работу без повышения уровня базы данных и отправляет уведомление, содержащее сообщение, возвращенное сценарием.
После повышения уровня базы данных до уровня мастера, в случае, если значение «auto.reconfigure» в конфигурации установлено на «true», остальные подчиненные узлы настроены для работы с новым главным сервером. Затем запускается скрипт «script.post.promotion» (все время на одной машине), результат этого скрипта не влияет на дальнейшую работу кластера, но он прикрепляется к уведомлению, отправляемому кластером EFM.
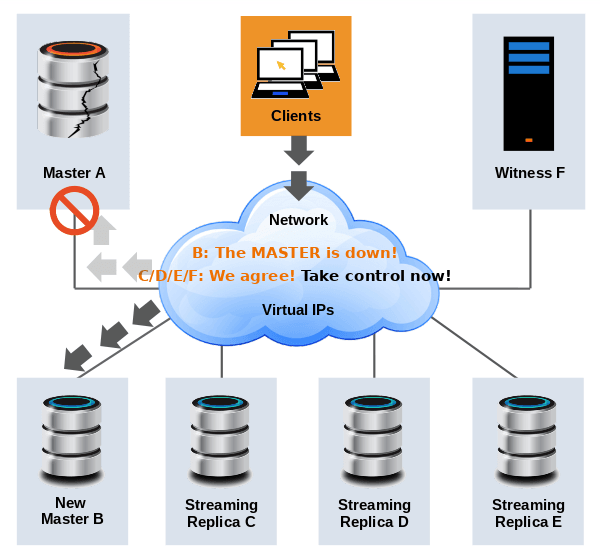 Работа кластера диспетчера аварийного переключения EDB
Работа кластера диспетчера аварийного переключения EDB
Диспетчер аварийного переключения EDB поддерживает следующие 6 рабочих сценариев. Подробное описание работы каждого из них со схемой можно найти в документации, доступной на сайте производителя по следующим ссылкам:
Недоступность главной базы данных. Недоступность ведомой базы данных. Агент или главный узел. Сбой агента или подчиненного узла. Сбой агента или следящего узла. Изоляция узла от кластера. Подчиненный кластер на основе других типов потоковой репликации поддерживается). Запуск/завершение работы кластера EFM не оказывает прямого влияния на репликацию. Репликация все еще выполняется, но не контролируется и не защищается от сбоя главного сервера.
Второе условие — установка виртуальной машины Java версии 1.8. Чтобы использовать встроенный механизм отправки уведомлений — по электронной почте — вам необходимо настроить механизм отправки SMTP на каждом из узлов.
Поддержка кластера
Чтобы проверить состояние кластера, используйте команду:
efm cluster-status efm
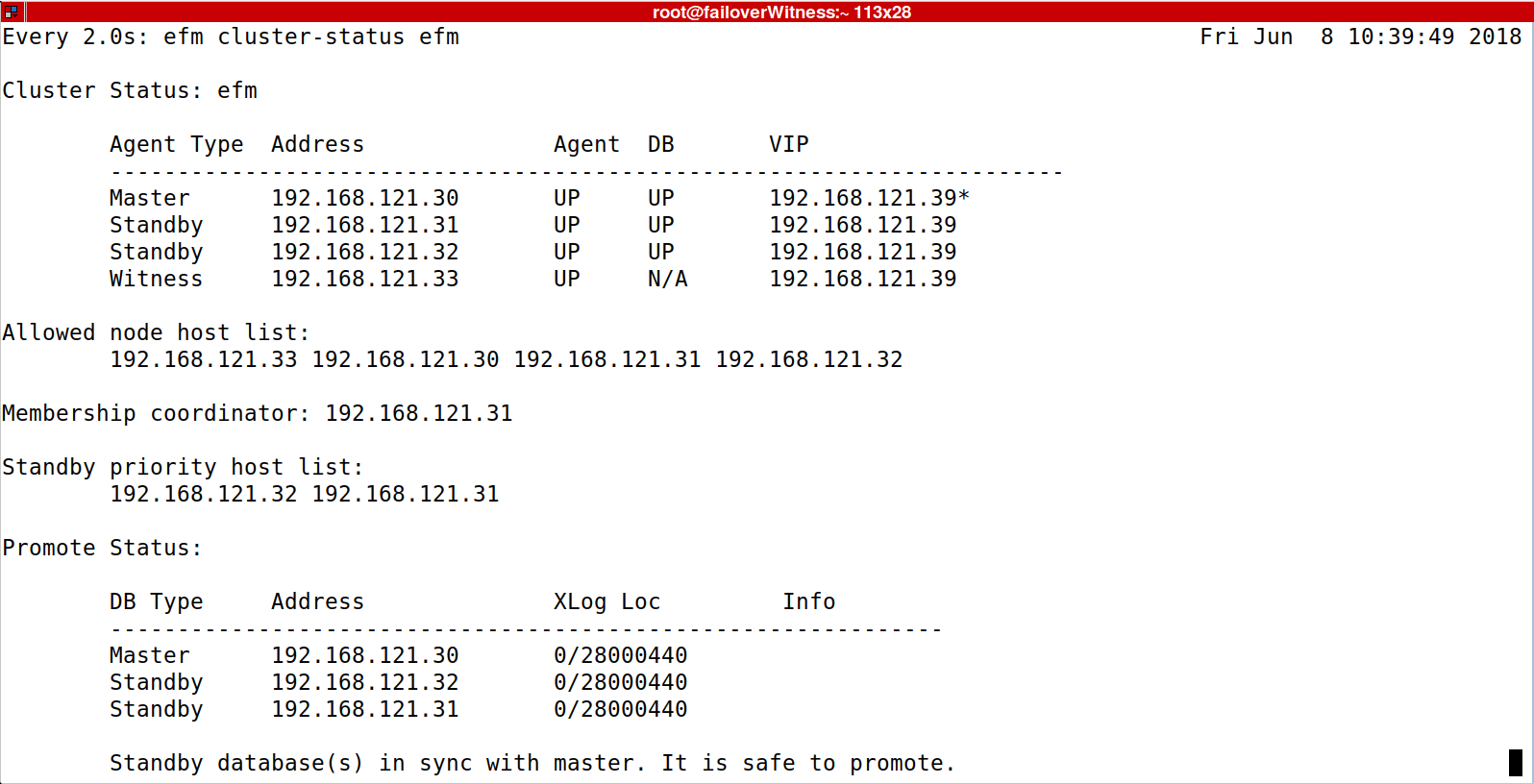 Эффект
Эффект
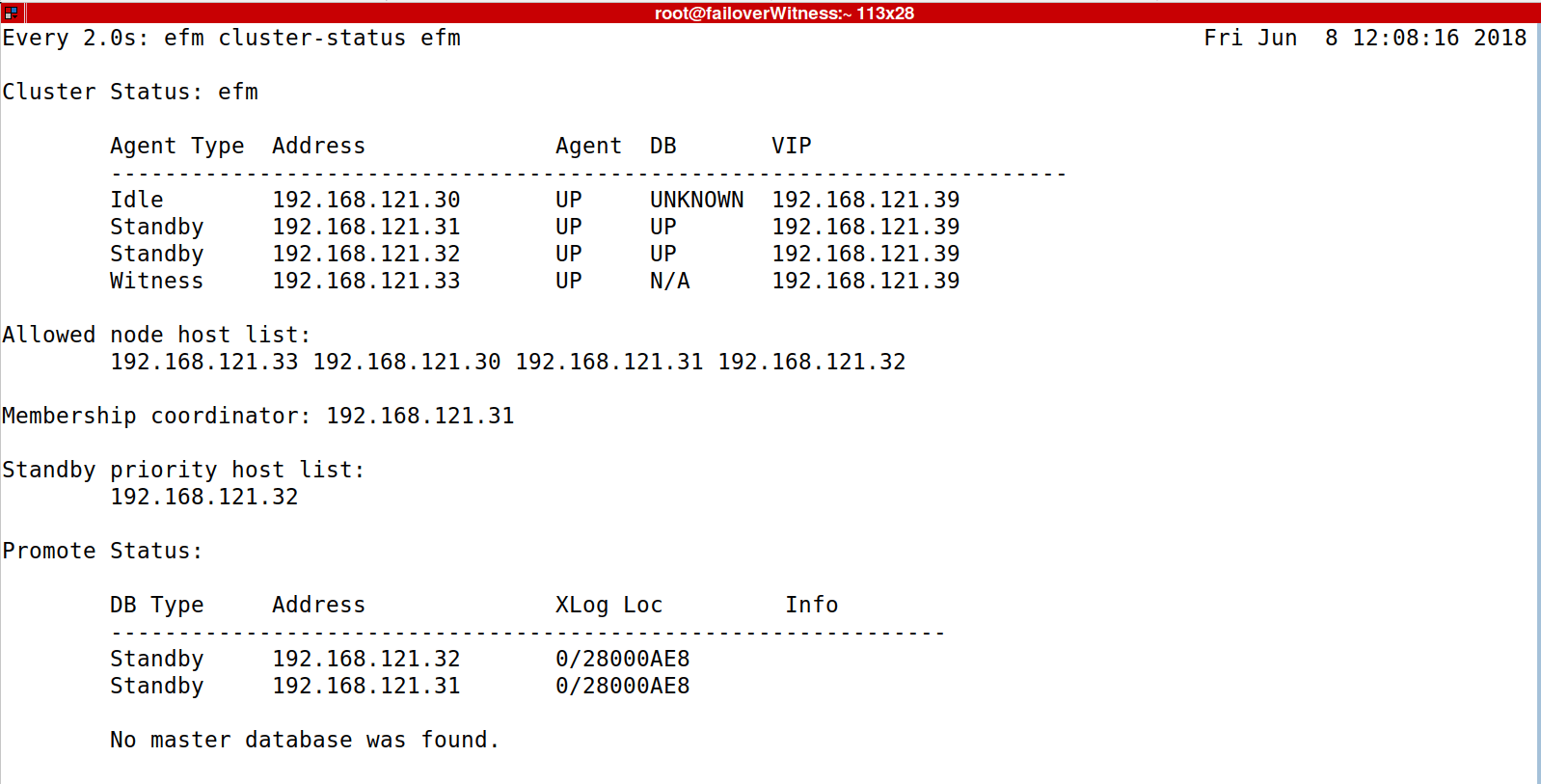
Как вы можете видеть на скриншоте выше: сервер 192.168.121.30 действует как главный, серверы 192.168.121.31, 192.168.121.32 действуют как подчиненные, сервер 192.168.121.33 действует как свидетель, и нет базы данных, участвующей в репликации. Координатор кластера — Служба агента, работающая на сервере 192.168.121.31.
«Список хостов с приоритетом ожидания» — отображает серверы, которые могут быть повышены до роли Master, в порядке приоритета. Самый важный критерий — это актуальность копии базы данных, но с помощью команды
efm set-priority efm 192.168.121.31 1
приоритет можно изменить.
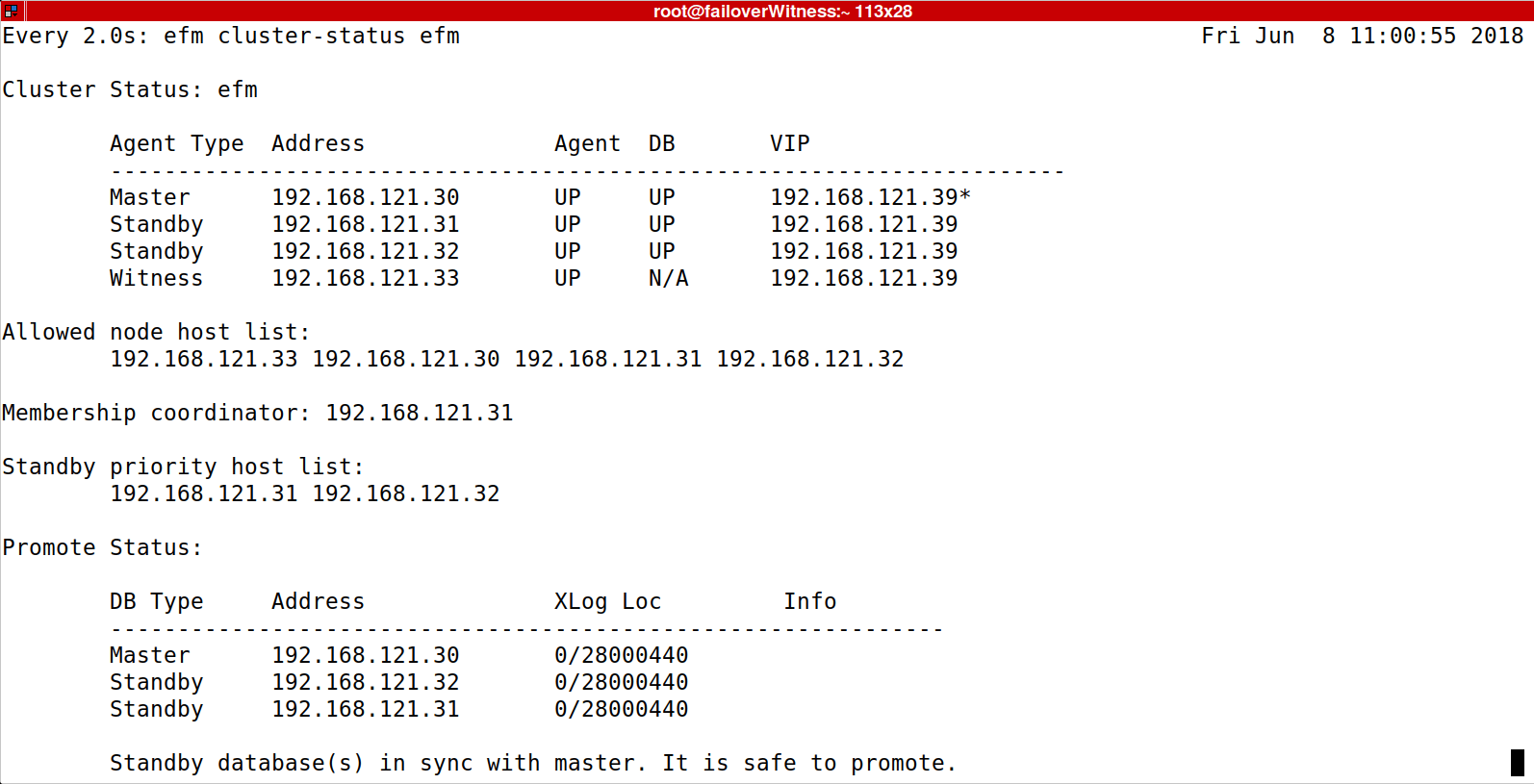 Эффект
Эффект
Значение 1 означает наивысший приоритет, установка приоритета 0 исключает сервер из этой очереди и, в результате его не продвигали на роль Мастера.
efm set-priority efm 192.168.121.31 0

Проверка статуса кластера также может быть автоматизирована путем создания результата JSON, который легко обрабатывать автоматически.
efm cluster-status-json efm
Пример вывода команды в & nbsp; .json формат
{«узлы»: {«192.168.121.30»: {«тип»: «Мастер», «агент»: «UP», «db»: «UP», «vip»: «192.168.121.39», «vip_active» : true, «xlog»: «0 /28000440», «xloginfo»: «»}, «192.168.121.31»: {«type»: «Standby», «agent»: «UP», «db»: » UP «,» vip «:» 192.168.121.39 «,» vip_active «: false,» xlog «:» 0 /28000440 «,» xloginfo «:» «},» 192.168.121.32 «: {» type «:» Режим ожидания »,« агент »:« UP »,« db »:« UP »,« vip »:« 192.168.121.39 »,« vip_active »: false,« xlog »:« 0 /28000440 »,« xloginfo »: «»}, «192.168.121.33»: {«type»: «Witness», «efm allow-node efm 192.168.121.30agent»: «UP», «db»: «N /A», «vip»: «192.168.121.39», «vip_active»: false}}, «allowednodes»: [«192.168.121.33», «192.168.121.30», «192.168.121.31», «192.168.121.32»], «координатор членства»: «192.168 .121.31 «,» failoverpriority «: [» 192.168.121.32 «],» minimumstandbys «: 0,» missingnodes «: [],» messages «: []}
Присоединение и отключение машин от кластера выполняется с помощью команд :
efm allow-node efm 192.168.121.30
интегрирует этот компьютер в кластер EFM и, таким образом, обеспечивает управление узлом с уровня EFM. Команда
efm disallow-node efm 192.168.121.30
исключает данную машину из кластера EFM. Обратите внимание, что простой запуск команды на работающем узле не отключает его от кластера EFM — он по-прежнему отслеживается и контролируется кластером EFM и может быть повышен до роли Master. Только перезапуск агента EFM на этом узле удалит его из кластера EFM. Однако, если там была настроена репликация, она все еще работает, пока мы ее не отключим, хотя невозможно отслеживать узел из EFM и повышать его до роли Master.
После остановки базы данных и ее перезапуска. (например, для работ по техническому обслуживанию), чтобы получить контроль, предоставляемый EFM, и возможность повышения до роли мастера, выполните команду
efm resume efm
Команда должна быть выполнена на узле, к которому она применяется. Без этой команды EFM выдает состояние бездействия базы данных («IDLE»), он отслеживает узел, но не позволяет повысить его до роли Master.
Остановка всего кластера, то есть остановка агент службы на всех узлах, включая свидетель, выполняет команду:
efm stop-cluster efm
Очень полезной опцией является команда для автоматического преобразования конфигурации старой версии в конфигурацию новая версия при обновлении версии программного обеспечения кластера. Его необходимо выполнить на каждом из узлов кластера.
/usr/edb/efm-3.1/bin/efm upgrade-conf efm -source /etc/edb/efm-3.0/
Наконец, оператор «продвинуть» продвигает узел до роли мастера. .
efm продвижение efm
Повышает первый подчиненный узел в очереди до роли главного и перенастраивает остальные узлы кластера (если иное не указано в конфигурации узла) для использования нового главного. Если инструкция выполняется в кластере с работающим мастером, новый мастер будет повышен. Подчиненные узлы будут настроены на его использование, но существующий мастер не будет отключен, хотя он перестанет участвовать в репликации.
Для автоматического продвижения нового мазера и переключения старого в подчиненный режим, используйте переключатель:
efm promotion efm -switchover
 Эффект
Эффект  Эффект
Эффект  Эффект
Эффект  Резервный агент запущен, и состояние базы данных отслеживается . Конфигурация сценария </p>
<p> Сценарии запускаются с правами пользователя efm% p — новый мастер% f — сбой [script.fence =/somepath/myscript% p% f] </p>
<p>script.fence путь к сценарию для запуска перед повышением нового мастера, запускается на узле, который будет повышен, в случае завершения сценария с результатом, отличным от успеха («0»), узел не будет повышен до роли Мастера. script.post.promotion путь к сценарию, запускаемому после продвижения нового мастера, на самом мастере код выхода из сценария будет отправлен в сценарии уведомления. возобновление выполнения до того, как служба Agentascript.db.failure восстановит мониторинг запущенного запуска базы данных после сбоя локальной базы данных script.master.isolated запускается на главном сервере после обнаружения его изоляции от остальной части clastrascript.remote.pre.promotion запускается на других серверах до того, как продвижение сервера slavescript.remote.post.promotion запускается на других серверах после slavescript.custom Скрипт продвижения сервера .monitors, который запускает дополнительный, собственный мониторинг, дополнительную конфигурацию скрипта: custom.monitor.interval — интервал запуска и скрипт в секундах custom.monitor.timeout — по истечении этого времени работа скрипта будет остановлена и будет отправлено уведомление custom.monitor.safe.mode — если установлено значение «true», отличное от «0», результат скрипта будет сообщено, но не вызовет статус сбоя повышения или распознавания </p>
<p> Связанные записи: </p>
<p> Что нового в EDB Postgres Failover Manager 3.2 </p>
<div class=)