
«id =» main «> Делитесь наукой, данными и бизнесом
Наука о данных как нечто большее, чем «обычный» статистический анализ данных, вопреки внешнему виду, не является новой отраслью информатики. Первые решения, особенно алгоритмы и методы, были разработаны в 1950-х и 1960-х годах (https://en.wikipedia.org/wiki/Timeline_of_machine_learning). Однако из-за относительно низкого уровня компьютеризации производственных процессов (также так называемого бизнеса), что привело к низкой доступности цифровых данных и относительно невысокой вычислительной мощности используемых вычислительных машин, они не получали особого внимания и не рассматривались. используется на практике. В результате такого положения дел был длительный (для ИТ) период, длившийся более десяти лет, когда эта тема бездействовала в контексте коммерческих ИТ-решений.
Большое возвращение этого явления началось в 80-х и 90-х годах прошлого века с первых попыток создания программного обеспечения, поддерживающего так называемые машинное обучение в коммерческих приложениях, например, прогнозирование экономических показателей на основе исторических данных и т. д. Следует также отметить, что в 1970-х годах наблюдался значительный рост уровня компьютеризации, в частности бизнеса, необходимого для популяризации этих решений.
Analyticum sapiens
«Наука о данных», как сказали бы римляне, «Nihil novi sub sole». Помимо того, что это очень модное в этом сезоне «модное словечко», вызывает трепет у сотрудников аналитических отделов, например, когда они слышат, что в компании появился новый Data Scientist.
Как Что касается терминологии, которая отличает эту область, я был бы осторожен, потому что на самом деле упомянутый «специалист по данным» — всего лишь немного более умный старый аналитик данных, который постоянно обновляет свои знания и набор инструментов, которые он использует. Так что с этого момента вместо слова «специалист по данным» я буду использовать термин «интеллектуальный аналитик данных».
Действительно, чтобы расправить свои профессиональные крылья и стать «мудрым аналитиком данных», рядовой аналитик данных должен расширить набор используемых аналитических инструментов (мы говорим о методах «подсчета»). Для этого в Интернете доступны отличные, готовые к написанию материалы — платные (с гарантией) и бесплатные, а также «on-line» курсы. Фактически, достаточно начать с различных «кирпичиков», которые помогут проверить наши возможности в области «расширенной» аналитики и решить, что делать дальше.
Обычной практикой является нанимать специалистов по данным вне организации вместо того, чтобы продолжать обучать проверенных и опытных бизнес-аналитиков.
Хотя эти люди обладают обширными предметными знаниями в области теории современных аналитических методов и технологий, они часто не имеют адекватных знаний о контексте анализа. На мой взгляд, это ошибка. По возможности лучше обучить проверенных аналитических кадров (если только она — этот персонал — этого не хочет), а вопросы технологий оставить инженерам — так называемым «Интеграторы» или отделы корпоративной архитектуры.
Разные потребности, разные инструменты, разные ограничения
В зависимости от того, как применяются методы машинного обучения, используются три основных типа инструментов, которые я кратко опишу в следующих параграфах.
Во-первых, мы могли бы сказать, что «первичная» модель, «автономный» анализ, в основном используется для разработки некоторой сложной аналитической модели для решения проблемы предметной области. В этом случае наиболее часто используются интегрированные аналитические среды, такие как RapidMiner, KNIME, IBM SPSS и т. Д., Которые в настоящее время «оснащены» различными надстройками, обеспечивающими методы машинного обучения. Чаще всего инструменты используются в «персональной» компьютерной среде аналитика, гораздо реже в качестве интегрированной аналитической среды для групповой работы (хотя большинство таких решений предоставляют возможность работы «на сервере»). Эта модель работы чаще всего подразумевает использование полуобработанных данных, хранилища данных, статистических баз данных и т. Д. И в основном подходит для определения определенных аналитических стратегий, редко когда результаты такой работы интегрируются в виде готовых решений в следующем. описал случай машинного обучения.
Более изощренный способ применения методов машинного обучения — их оперативное использование. А именно, использование различных, более или менее продвинутых, контролируемых (а иногда и неконтролируемых) алгоритмов обучения для реализации определенных конкретных, высоко компьютеризированных фрагментов бизнес-процессов, особенно связанных с принятием решений в области снижения рисков. Примером может служить система выдачи кредитных решений, в которой так называемые «Оценка» (скоринг) доверия клиентов осуществляется, в том числе, на основе автоматического отнесения его к определенным группам на основе набора присущих ему функций, а их может быть даже более 1000 (включая функции, описывающие, например, текущую кредитную историю и т. д.). Эти типы моделей чаще всего поставляются в виде готовых систем, которые выполняют эту задачу, например Experian Scorex. Но они также создаются внутри организации — в этом случае все зависит от специфики «цепочки создания стоимости» и процессов, которые ее реализуют.
Вышеупомянутые методы имеют ряд ограничений, связанных (в первом случае) с доступностью, повторяемостью и повторным использованием разработанных моделей или (во втором случае) с их универсальностью (решения предметной области). При этом, как уже упоминалось, оба случая применения машинного обучения или аналитического моделирования в целом сильно зависят друг от друга.
Может пригодиться решение, сочетающее в себе простоту выполнения анализа и возможность интеграции с другими ИТ-решениями. Возникает вопрос, существует ли такая вещь в целом или кто-то в одном решении может обеспечить скорость и системную интеграцию сложных продуктов баз данных и облегченной аналитической среды, в которой мы можем свободно экспериментировать с данными и методами. Ответ: «да, но …» А теперь серьезно … такое решение можно успешно использовать Splunk Enterprise вместе с расширением (также называемым Splunk) Machine Learning Toolkit (MLT).
Ну вот и это. Splunk MLT
Исходное описание звучит так:
«Набор инструментов машинного обучения Splunk помогает вам применять различные техники и методы машинного обучения, такие как классификация (прогнозирование положительного или отрицательного ответа), регрессия, обнаружение аномалий и обнаружение выбросов в отношении ваших данных».
В медленном, упрощенном переводе:
«MLT поможет вам применить к вашим данным различные техники и методы машинного обучения, такие как классификация, регрессия, обнаружение аномалий и отклонений».
И я, как так называемый «Spunk», могу только добавить, что Splunk в этом описании крайне скромен. Фактически, использование некоторых функций этого решения (Splunk + MLT), кстати, на основе библиотек, поддерживающих программирование машинного обучения Python, позволяет создавать расширенный анализ всех видов данных. Splunk обычно ассоциируется с анализом технических данных, то есть системных журналов, показателей и т. Д., Но его можно успешно использовать в качестве расширенной базы данных всех видов бизнес-событий с особым упором на их временную последовательность (Splunk, в конце концов, , продвинутая реализация так называемой базы данных временных рядов базы данных). Что даже дает ему определенное преимущество перед аналитическими системами, основанными на всеобъемлющей, но по своей сути статической реляционной модели (тот, кто создает хранилища данных с временными измерениями, знает, о чем я говорю).
Splunk MLT — удобный инструмент аналитического моделирования, вплетенный в язык запросов Search Processing Language (SPL). Язык SPL был разработан специально для выполнения зачастую чрезвычайно сложного анализа данных в «конвейерной» модели способом, аналогичным тому, который наиболее знаком с процессами ETL, используемыми в складских системах. Однако главное отличие состоит в том, что он позволяет вам задавать вопросы и обрабатывать данные интерактивным (даже разговорным) способом, который мы знаем из сред SQL. И, вероятно, в этом самое большое преимущество использования системы Splunk, среда дает беспрецедентную комбинацию аналитической универсальности, известной из продвинутых доменных систем (BI, отчетность), с легким доступом к информации, известной из так называемых Базы данных OLTP (обработка транзакций в режиме онлайн) или хранилища данных, и, кроме того, у нас есть ряд команд, использующих методы машинного обучения.
Практика машинного обучения — от структуры к выводам
Во время аналитической работы, также связанной с машиной В обучении можно выделить несколько характерных этапов:
анализ структуры и взаимосвязи данных; анализ значения данных и информации, содержащейся в них; подготовка схемы или модели анализа (чаще всего путем эксперимента или опыта), чаще всего в отношении некоторой гипотезы; применение модели: синтетические обобщения, визуализация и интерпретация полученных результатов.
В случае традиционного подхода каждый из этих этапов обычно требует специализированных инструментов. Например, этап предварительной обработки данных, в связи с их «происхождением» из реляционных баз данных, осуществляется на основе документации схем и их возможного преобразования с использованием методов ETL (extract, transform, load). Только после этого обработанные, часто «сглаженные» данные подходят для использования в широко понятной аналитике, включая подготовку статистических моделей, машинное обучение и т. Д.
Так было (было) с реляционными источниками. Несколько иная ситуация в случае более структурно разнородных данных, так называемых «Большие данные», которые могут безопасно включать в себя всевозможные записи, регистры, связанные с ходом процессов, кроме того, особенностью такой информации является временная составляющая, которая часто используется как важный фактор (например, анализ вероятности последовательности событий в процессе (поток кликов и т. д.).
В случае сильно различающихся данных традиционные методы перестают быть эффективными, и необходим инструмент, ориентированный на этот тип информации. Одним из таких решений является система Splunk Enterprise с подходом «схема на лету» и различными другими функциями, которые позволяют анализировать большие объемы сильно дифференцированных данных. Благодаря этому это система, или фактически системная платформа, идеально подходящая для использования в области машинного обучения, работающего с «большими данными».
Обратите внимание, что, устанавливая дополнительные компоненты на платформу Splunk в виде Python для научных вычислений и набора инструментов машинного обучения, мы получаем полнофункциональную аналитическую среду, которая позволяет нам выполнять структурирование (извлечение) и любые преобразования данных с использованием языка SPL, а также дополнительно имеет полный (практически) набор часто используемых алгоритмов машинного обучения с возможностью реализации собственных решений в виде последовательных элементов языка SPL. Кроме того, система Splunk отличается продуманным и интуитивно понятным графическим интерфейсом (визуализация данных). Это дает практически неограниченные возможности построения специализированных (предметных), общих (коллективная работа) аналитических сред.
Пример приложения MLT
Давайте подробнее рассмотрим возможности Splunk MLT на примере данных о недвижимости.
Вначале, прежде чем мы начнем наше практическое приключение, позвольте мне добавить, что я совершенно не знаком с рынком недвижимости. , так что это пример случая «умного» аналитика, работающего с совершенно новой проблемой. Данные, которые я использовал, доступны как образцы данных в Splunk MLT.
Сам эксперимент, очевидно, является упрощением реального процесса обучения машинному обучению, но он может дать обзор специфики работы в этой области анализа данных.
Что касается самих методов машинного обучения, то, к сожалению, они есть. В этой статье нет места для подробностей, но для технических специалистов и аналитиков в качестве введения в методы машинного обучения я могу честно порекомендовать веб-сайт dr. Джейсон Браунли: & nbsp; https: //machinelearningmastery.com
Пора начинать эксперимент
Мы получили выборку из 506 точек продажи недвижимости со статистическими данными, такими как среднее значение, полученное во время продажи; как и откуда, как мы получили данные — тема отдельной статьи. Местоположение собственности описывается 12 функциями, ниже представлен образец набора данных для нескольких местоположений.
 Пример набора данных для нескольких местоположений
Пример набора данных для нескольких местоположений
Цель эксперимента — подготовить модель машинного обучения, которая наилучшим образом предсказывает среднюю стоимость дома с заданными параметрами.
Во-первых, мы исключаем места с самым высоким уровнем преступности из дальнейшего анализа и параметризации модели ML. Мы делаем это с помощью метода отсечения процентилей в соответствии с указанной функцией, меня интересуют только места с показателем ниже 75-го процентиля для данной области (land_zone). Таким образом можно подготовить статистическую выборку, используя соответствующий язык SPL.
& lt; source data> | eventstats perc75 (Crime_rate) как cutoff_crime_rate по land_zone | где Crime_rate & lt; cutoff_crime_rate | …
Просто не правда ли? Можно сказать, что синтаксис команды очень простой и интуитивно понятный. Оператор потока «|» он имеет точно такое же приложение, что и среда оболочки POSIX.
Если бы у нас был большой набор данных, Splunk MLT дает нам дополнительную команду & nbsp; sample, которую мы могли бы использовать для псевдослучайного генерирования статистических данных. sample — мы не будем использовать его здесь, потому что набор данных в нашем распоряжении еще невелик. Но это могло выглядеть так:
& lt; source data>| коэффициент выборки = 0,1 | eventstats perc75 (Crime_rate) как cutoff_crime_rate по land_zone | где Crime_rate & lt; cutoff_crime_rate | …
Затем, когда мы подготовили основу набора данных для нашего эксперимента с машинным обучением, мы можем перейти к следующему этапу подготовки к обучению с учителем: выбору интересных функций (подробнее вы можете прочитать здесь: https: //machinelearningmaster. com/an-Introduction-to -feature-selection /)
Вот как мы выполняем первые два шага в мастере экспериментов Splunk MLT ML.
 Первый шаг в мастере эксперимента ML в Splunk
Первый шаг в мастере эксперимента ML в Splunk  покажет мне те из них, которые больше всего влияют на функцию, к которой относится эксперимент, так называемые цель (median_house_value). Кроме того, у нас есть возможность выбрать целевой режим лечения, например, следует ли рассматривать его как числовое или кардинальное значение (группирование) и алгоритм выбора (мы выбираем K-лучший, для меня это дало наилучшие результаты). </p>
<p>Как видите, у нас уже есть место для экспериментов с различными параметрами обработки данных. Но благодаря простому интерфейсу и простоте настройки мы можем сделать это без ненужного ожидания (например, для компиляции), чтобы изменить весь процесс. Это большое преимущество среды Splunk. </p>
<p> Затем, когда у нас есть начальная параметризация, мы можем перейти к реальной части эксперимента. В нем мы займемся выбором оптимального алгоритма машинного обучения, что иногда является нетривиальной задачей. </p>
<p>Мы можем выбирать из ряда предопределенных алгоритмов, наиболее часто используемых в практическом машинном обучении. В рамках эксперимента по созданию модели прогнозирования мы будем иметь дело с двумя довольно популярными в использовании: линейной регрессией и алгоритмом дерева решений. </p>
<p>Первый шаг — это алгоритм линейной регрессии. В поле «Поле для прогнозирования» выберите свойство цели прогнозирования (median_house_value). В поле «Поля для использования для прогнозирования» укажите поля, которые будут включены в прогнозирующую модель. Также стоит указать параметр, указывающий соотношение разделения набора данных на обучающий и проверочный. Данные обучения будут использоваться для настройки модели, а данные проверки будут использоваться для проверки ее эффективности путем проверки коэффициента детерминации (R2) и ошибок прогноза (RMSE). </p>
<p> После ввода параметров, запускаем процесс обучения (кнопка «Fit»). </p>
<p> Ниже представлены результаты в графическом виде, представленные в приложении после выполнения задания. </p>
<p> <img src = )
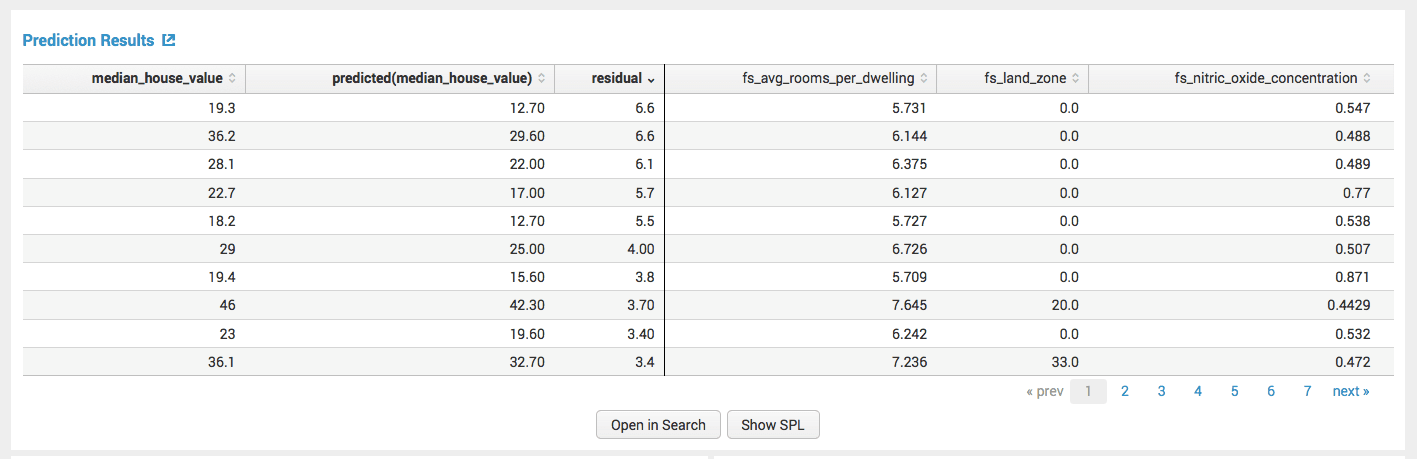
В первом разделе вы можете увидеть входные данные и результат прогноза вместе с конкретной ошибкой (разницей). В следующем «Actual vs. Прогнозируемый … «показывает различия, ошибки в прогнозе, сделанном алгоритмом прогнозирования.
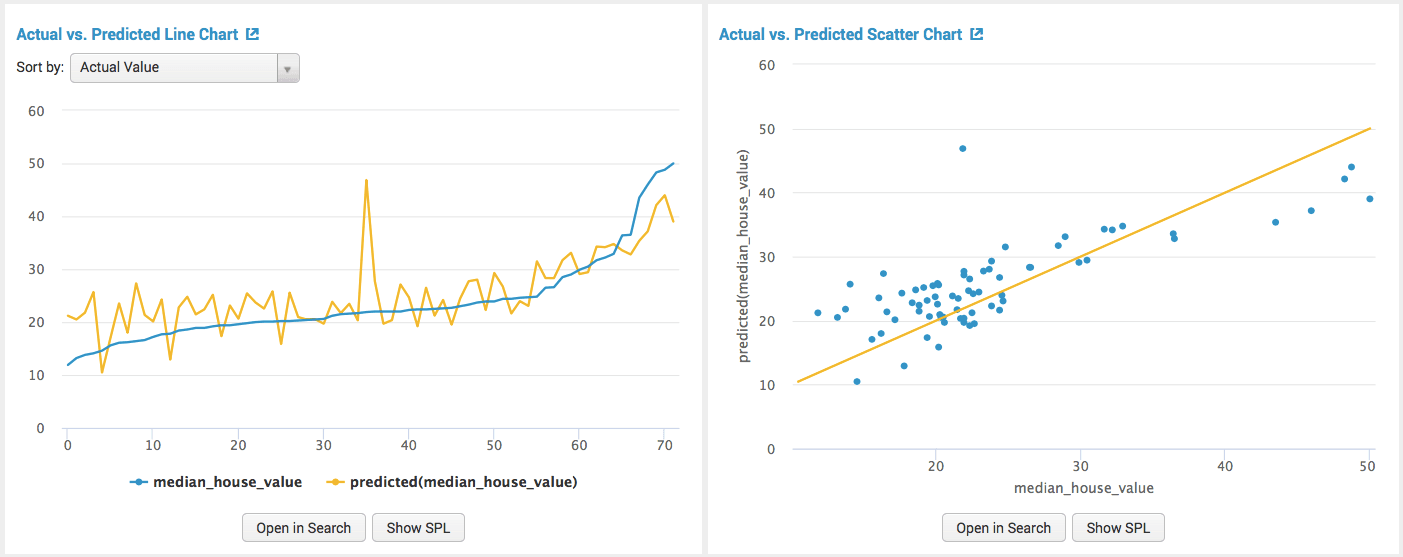 показывает различия, ошибки в прогноз, сделанный алгоритмом прогнозирования
показывает различия, ошибки в прогноз, сделанный алгоритмом прогнозирования  Результат прогноза с определенной ошибкой
Результат прогноза с определенной ошибкой
В последнем разделе показаны коэффициенты детерминации и отклонения для выбранного метода ML. Они используются в случае практического выбора метода в качестве сравнительных величин.
На этом этапе основная задача — выбрать метод с наименьшей «относительной» ошибкой, т.е. с коэффициентом детерминации. как можно ближе к значению 1. В предыдущем случае для заданных параметров мы получили значение 0,5441. Итак, давайте посмотрим, как другой метод машинного обучения, алгоритм дерева решений, ведет себя с теми же входными параметрами.
Вот результаты (наиболее важные) для метода дерева решений.
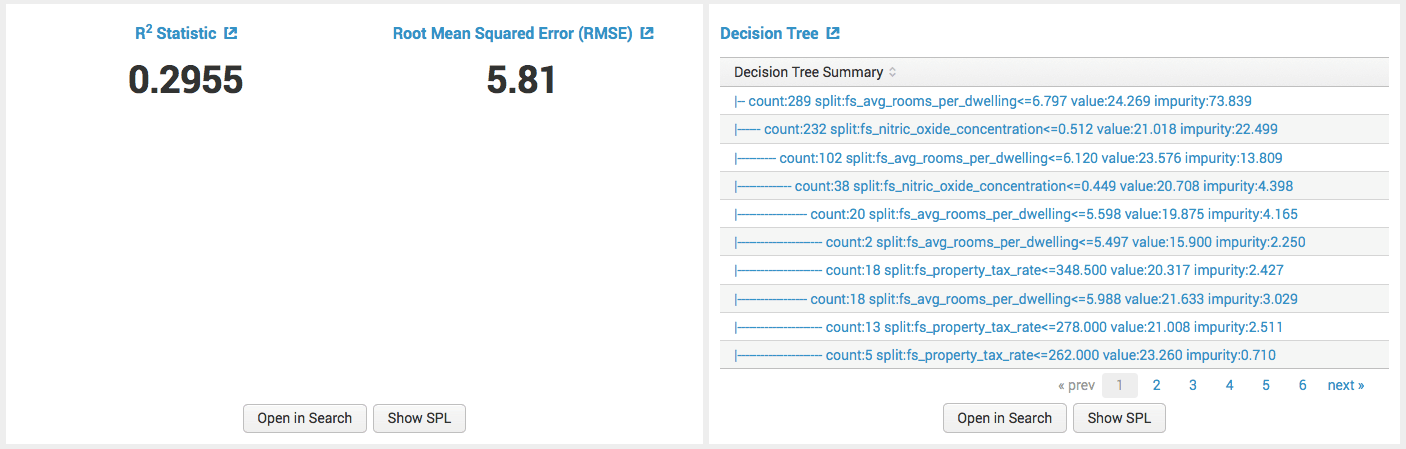 методы дерева решений
методы дерева решений
Как вы можете видеть на прилагаемом рисунке, метод 2 показал себя немного хуже, и он показывает (как определено в) значение коэффициента детерминации.
Заключение
Вывод содержится в лингвистической конструкции, из которой построена канва для всей статьи.
| inputlookupousing.csv | eventstats perc75 (Crime_rate) как cutoff_crime_rate по land_zone | где Crime_rate & lt; cutoff_crime_rate | соответствует FieldSelector «median_house_value» из «avg_rooms_per_dwelling», «charles_river_adjacency», «Crime_rate», «distance_to_employment_center», «Highway_accessibility_index», «land_zone», «nitric_oxide_conestation», «property_bield_bield»> вписать LinearRegression fit_intercept = true «median_house_value» из «fs_ *» в «example_housing»
Таким образом, с помощью пяти команд в одном запросе SPL, созданном в интерактивном графическом мастере, мы приручили небольшой «искусственный интеллект» (или, по крайней мере, его основной компонент) и построили модель, прогнозирующую приблизительные цены на недвижимость где-то в Соединенных Штатах Америки. Вероятно, такая же степень сложности будет применима к нашим польским реалиям или другим проблемам из других областей бизнеса.
Обратите внимание, что все этапы анализа (может быть полезна панель инструментов для агента по недвижимости) были выполнены в единая согласованная аналитическая среда, потому что без опасений можно назвать Splunk Enterprise.
Подводя итог этому простому эксперименту, следует также отметить, что это, конечно, еще не все. Теперь эту модель («example_housing») можно использовать для прогнозирования цен на недвижимость для новых данных (с набором функций, которые мы использовали для построения модели). И используйте Splunk Enterprise API для создания веб-сайта, который использует местную статистику для определения приблизительных цен на недвижимость. Но это тема для совершенно другой статьи.
Привет от «спанкера» — счастливого Splunking!