
«id =» main «> Поделиться
Глубокое обучение переживает бум в последние несколько лет. Если вы хотите попробовать этот подход к анализу данных, вот несколько советов по настройке популярных сред: TensorFlow и Keras. Обе инфраструктуры подходят разработка — также в области параметров конфигурации, поэтому, чтобы иметь возможность использовать эти советы, стоит проверить версии ваших собственных сред. Выбранные параметры описаны с использованием Python версии 3.5.3, TensorFlow версии 1.4.1 и Keras версии 2.1 .3.
Я предполагаю, что у читателя есть компьютер с видеокартой, и он хотел бы использовать его в процессе глубокого обучения. Первый, фундаментальный вопрос: действительно ли наша программа сможет использовать графический процессор или только центральный процессор. Ниже приведен код Python, который отвечает на этот вопрос путем печати набора устройств, с которыми может работать установленная версия TensorFlow.
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Если вы используете Python из ветки 2.x, предварительно импортируйте функцию с помощью следующей директивы:
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Представленный диагностический код дает идентификаторы доступных устройств, на которые мы можем ссылаться в аналитическом коде, о котором чуть позже. В моем рабочем месте TensorFlow может работать как с процессором, так и с графическим процессором.
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
TensorFlow позволяет настраивать сеанс с помощью функции ConfigProto (). Если, например, мы хотим проверить, какие устройства реализуют отдельные элементы аналитического графа, мы вызываем экземпляр упомянутой функции и параметризуем его. В качестве примера давайте посмотрим, какие устройства используются для умножения матриц:
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Благодаря опции активации & nbsp; log_device_placement & nbsp; вы можете видеть, что в моем рабочем месте операции с графом — как создание матрицы, так и умножение матриц — выполняются видеокартой с идентификатором GPU: 0
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Однако ничто не мешает вам изменить его, если для данного устройства была реализована определенная операция. Мы вызываем идентификатор целевого устройства, назначая ему запрошенную операцию:
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
В результате прямого присвоения, как указано выше, создание выбранных матриц (a2, b2) и операция их умножения (F) теперь выполняются CPU, а остальные операции с графом — GPU.
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Чтобы избежать возможных ошибок, связанных с отсутствием реализации определенных операций для целевого устройства , указав их, стоит заявить о возможности прямого присвоения. Мы используем следующие параметры:
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Если, например, мы заявили, что часть кода, связанная с обучением сети, должна выполняться полностью на графическом процессоре и для правильного обратного распространения с использованием определенного алгоритма (например, RMS) , участие ЦП обязательно, указанная выше опция избавит нас от ошибки. Фрагмент кода, который не может быть выполнен на GPU, будет выполнен на CPU.
Удобная библиотека Keras часто используется для быстрого прототипирования. На его уровне мы также можем ссылаться на параметры конфигурации сеансов Tensorflow, если этот фреймворк, конечно, является серверной частью. Чтобы параметризовать сеанс TensorFlow с помощью библиотеки Keras, используйте функцию set_session (), как показано ниже.
 Глубокое обучение — полезная конфигурация параметры
Глубокое обучение — полезная конфигурация параметры
Важно, чтобы конфигурация сеанса TensorFlow предшествовала импорту серверной части.
Другой полезный вариант конфигурации — это директива, связанная с управлением памятью графического процессора. По умолчанию TensorFlow пытается выделить максимальный объем ресурсов памяти на карте для текущего сеанса, независимо от того, сколько памяти действительно требуется процессу. Так, например, попытка параллельного тестирования альтернативной модели — по крайней мере, с параметрами, отличными от текущей модели — потерпит неудачу. Чтобы предотвратить это, мы выпускаем такую директиву:
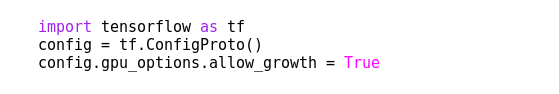 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Этот параметр распределяет ресурсы памяти карты GPU в соответствии с фактическими потребностями сеанса. Теперь мы можем тестировать альтернативные сетевые модели параллельно, если общий объем памяти, используемый параллельными сеансами, не превышает общий объем памяти видеокарты. В случае карт NVIDIA мы можем удобно отслеживать состояние ресурсов графического процессора, введя в терминале следующую команду:
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Ниже приведен пример результата вышеупомянутой команды, выданной во время параллельного обучения двух альтернативных классификаторов на основе сети Vgg16 с использованием классических данных MINIST, встроенных в библиотеку Keras.
 Глубокое обучение — полезные параметры конфигурации
Глубокое обучение — полезные параметры конфигурации
Как видите, параллельное обучение двух альтернативных классификаторов занимает менее 600 Мб памяти из 4 Гигабайт, имеющихся на ноутбуке. Оба классификатора содержат около миллиона оптимизированных параметров.
Благодаря параметрам конфигурации, обсуждаемым в статье, вы можете добавить еще четыре альтернативные модели аналогичной сложности к параллельным тестам и, например, отправиться на обед.
См. также: Глубокое обучение — лекарство от зла или глубокое обучение в борьбе с киберпреступностью
См. также: Искусственный интеллект в новой версии — Tensorflow 2.0 облегчит построение нейронных сетей