«id =» main «> Поделиться
Облачные вычисления стали очень популярной темой в последнее время. Многие учреждения рассматривают возможность перевода своей инфраструктуры на облачные решения.
Использование гибридного облака дает ряд преимуществ . Пользователь платит только за то, что фактически использует, не выставляется авансовый счет за весь месяц, вместо этого взимается почасовая оплата. Еще одним преимуществом гибридного облака является упрощение процесса обслуживания инфраструктуры, что требует гораздо меньше усилий от команды. .
Почему OpenShift? Платформа OpenShift?
Red Hat OpenShift и Red Hat Ansible в облаке позволяют легко горизонтально масштабировать так называемые «Уменьшить масштаб». OpenShift — это инструмент, который обеспечивает среду для запуска приложений, которые благодаря использованию контейнеризации намного «легче», чем решение, основанное на виртуализации. Платформа OpenShift упрощает переносимость и масштабирование приложений. «Легкость» контейнеров обусловлена функциональностью пространств имен и групп, которые вместе с selinux создают безопасное и эффективное решение. Если нам нужна максимальная производительность и безопасность, OpenShift также поддерживает RHEL Atomic Host.
См. Также: OpenShift 4.1 теперь доступен
OpenShift имеет ряд инструментов для управления и мониторинга контейнеров/приложений, включая механизм «горизонтального автоматического масштабирования». Это обеспечивает автоматическое горизонтальное масштабирование наших приложений в зависимости от использования процессора или памяти на узлах — машинах, используемых для запуска контейнеров. Подробнее об этом механизме я напишу в следующей статье.
Если OpenShift позволяет легко масштабировать, зачем мне Ansible?
Что, если ресурсы полностью используются на узлах, на которых работают контейнеры, и мы хотели бы легко расширить инфраструктуру, на которой работает Red Hat OpenShift? Нам на помощь приходит Ansible, который в сочетании с гибридным облаком ускоряет и облегчает создание и настройку новых узлов, на которых будут запускаться контейнеры.
Ansible — это инструмент, используемый DevOps для автоматизации управления конфигурацией программного обеспечения . Он имеет множество преимуществ, в том числе:
сотрудничает с самыми популярными поставщиками облачных решений, такими как Amazon AWS, Google Cloud Platform, Azure, и поддерживает системы Linux и Windows; он безагентный — для его работы не требуется установка агента на стороне клиента, канал ssh/winrm и ключи ssh должны быть предоставленным; использует идемпотентный механизм, который позволяет запускать модуль только тогда, когда изменения отмечены в файле конфигурации приложения, благодаря чему процесс мониторинга не является обременительным для клиентов; он прозрачен благодаря скриптам, написанным на yaml и структуре на основе модулей как для администратора, так и для разработчика.
Таким образом, благодаря Red Hat Ansible и огромному количеству модулей у нас есть один инструмент, который позволяет вам работать со многими решениями. Начиная от установки и настройки программного обеспечения, через настройку сетевых устройств и заканчивая реализацией инфраструктуры в облаке, о чем мы кратко поговорим.
См. Также: DevOps — «симфония компетенции »
Я хочу попробовать OpenShift в гибридном облаке. Что мне делать?
В этой статье я сосредоточусь на Microsoft Azure как на примере гибридного облака, которое предоставляет инфраструктуру, на которой работает OpenShift. Я продемонстрирую, как с помощью Ansible мы можем расширить существующую инфраструктуру OpenShift, добавив дополнительный узел, который будет использоваться контейнерами. Какие требования мы должны выполнить, чтобы начать приключение с OpenShift в Azure? Прежде всего, нам нужна лицензия. Конечно, мы можем использовать тестовые лицензии, доступные по следующим ссылкам:
Пробная версия OpenShift Пробная версия Azure
Есть много способов запустить OpenShift на гибридной платформе. В целях разработки я использовал 30-дневную пробную версию платформы Azure, на которой был реализован OpenShift Origin.
Если вы заинтересованы в доставке OpenShift в облаке таким поставщикам, как Microsoft, Amazon, Google или IBM & nbsp; свяжитесь с нами.
Кратко об архитектуре OpenShift в гибридном облаке
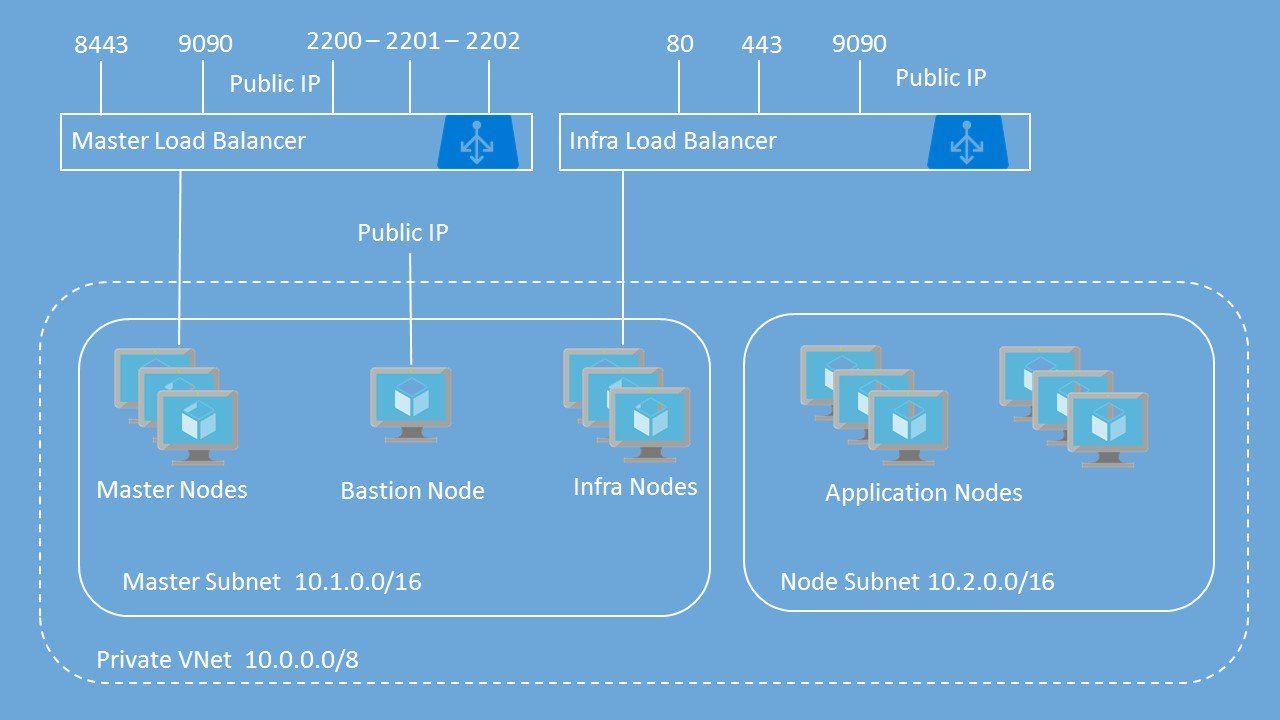
На рисунке ниже показана архитектура, построенная в гибридном облаке. Он содержит ряд компонентов, которые отвечают за работу OpenShift, в том числе:
«Главные узлы» — отвечают за предоставление Web-UI, etcd, API и других механизмов, отвечающих за хранение информации обо всей инфраструктуре OpenShift. «Инфра-узлы» — отвечают за запуск модулей/контейнеров, необходимых для работы OpenShift. Это все важные компоненты, без которых платформа не была бы полностью функциональной, в т.ч. роутеры (haproxy) и реестр. Благодаря контейнеру haproxy этот узел (узлы) направляется для трафика, поступающего извне к службам и, наконец, к нашим модулям/контейнерам. «Узлы приложений» — узлы, которые были разделены по соображениям безопасности. Они несут ответственность за запуск созданных нами контейнеров/приложений. По умолчанию контейнеры видны только во внутренней сети OpenShift через функцию «Маршруты». Содержимое контейнера публикуется с помощью механизма haproxy «Bastion Node» — дополнительного узла, который использовался на этапе доставки OpenShift в гибридном облаке для установки и настройки OpenShift на других узлах. Этот узел имеет возможность связываться с каждым узлом в сети и будет использоваться для масштабирования инфраструктуры «балансировщиков нагрузки», отвечающих за обеспечение высокой доступности. В нашей архитектуре мы выделяем два «балансировщика нагрузки», которым назначаются общедоступные адреса и публикуются соответствующие порты. Первый «Master Load Balancer» отвечает за перенаправление трафика на «Master Nodes». Второй перенаправляет трафик на Infra Nodes. Узлы приложений могут связываться только с другими узлами внутренней сети.
Модель OpenShift позволяет создать безопасную и эффективную платформу для масштабирования приложений.
 эффективная платформа для масштабирования приложений
эффективная платформа для масштабирования приложений
См. Также: Введение в проблемы безопасности на платформе Red Hat Openshift
Мы масштабируем инфраструктуру OpenShift в Azure
Чтобы запустить playbook/script, операционная система или «узел бастиона», который будет использоваться для связи с Azure API, должна быть должным образом подготовлена. Установите соответствующие пакеты, необходимые Python, которые необходимы для работы модулей Azure в Ansible.
$ sudo yum install ansible python-devel git -y
Установите диспетчер пакетов pip и пакеты, необходимые для связи с Azure API.
$ sudo easy_install pip $ sudo pip install package azure azure-storage
После завершения процесса начальной настройки нам необходимо передать переменные Ansible, которые будут использоваться в процессе проверки подлинности и связи с API Azure. Конечно, на этом этапе есть много способов предоставить информацию в Red Hat Ansible и сами механизмы аутентификации, например:
Решение «Service Principal» — намного безопаснее, но требует создания «Application», а затем создания и назначения «Resource Group», в которой будет работать наше приложение — обязательный метод в производственной среде. Пользователь, созданный в службе Active Directory на платформе Azure. Этот метод аутентификации обеспечивает полный доступ для внесения изменений в платформу Microsoft Azure, снижая при этом безопасность — метод не рекомендуется в производственных условиях.
В этой статье я буду использовать второе решение, использующее аутентификацию на основе учетной записи AD, что позволит нам упростить весь процесс. Следующие переменные среды необходимо экспортировать, чтобы Ansible мог взаимодействовать с API Azure. Если вы хотите, чтобы переменные были доступны после перезапуска компьютера, добавьте следующие записи в & nbsp; ~/.bash_profile & nbsp; или & nbsp; /etc/profile.d:
export AZURE_AD_USER = «» export AZURE_PASSWORD = «» экспорт AZURE_SUBSCRIPTION_ID = «6e97d9f4 -xxxx-49ae-xxxx-0d6f6632ffff»
Ansible ищет информацию об учетных данных во многих местах, в том числе w & nbsp; ~/.azure/credentials. Все зависит от варианта использования. Наши переменные содержат информацию о пользователе и пароле, с которыми мы выполняем вход на платформу Azure, и о подписке, номер которой можно просмотреть после входа в учетную запись и открытия ресурса «Подписки/Подписки» (в зависимости от языковой версии). Ниже приведен снимок экрана.
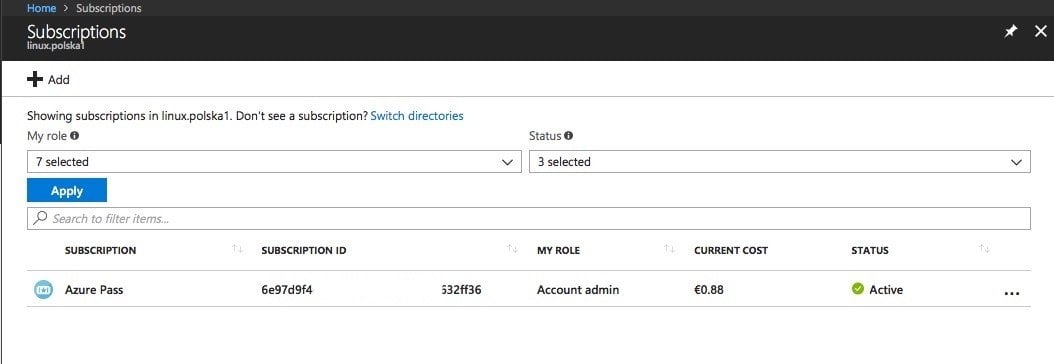 Подписки
Подписки
После добавления записей в ~/.bash_profile не забудьте обновить наши переменные в система, выполнив команду:
$ git clone https://github.com/Qwiatu-LinuxPolska/azure-ansible-openshift.git $ cd azure-ansible-openshift
Перед запуском скрипта ansible-openshift-add-app-node.yml нам нужно позаботиться об указании переменных, которые указаны в разделе «var». Ниже приводится краткий комментарий по каждой из переменных:
rg_name: & nbsp; «ocplinuxpolska» — имя группы ресурсов, в которой работает инфраструктура OpenShift; rg_location: & nbsp; «eastus» — расположение группы ресурсов, в которой работает платформа OpenShift; vnet_name: & nbsp; «openshiftvnet» — имя виртуальной сети; vnet_subnet_name: & nbsp; «nodesubnet» — имя подсети, из которой будет назначен ip-адрес для создаваемого узла; vm_name: & nbsp; «s1» — имя узла; vm_user: & nbsp; «ocpadmin» — имя пользователя, которое будет создано и использовано для процесса входа через Ansible; vm_passwd: & nbsp; «TajneHasło03 @» — пароль для нашего пользователя; ssh_public_key: & nbsp; «ssh-rsa AAAAB3 … «- открытый ключ, который будет внедрен в виртуальную машину в процессе создания.
Следующие переменные определяют сервер, содержащий необходимые сценарии воспроизведения, который отвечает за добавление узлового компьютера в платформу Red Hat OpenShift. В нашем случае таким узлом является «Bastion Node», который из-за более ранней поставки OpenShift имеет необходимые скрипты:
vm_deployment_public_ip: & nbsp; «52.16.1.82» — публичный адрес «Bastion Node»; vm_deployment_ssh_port: & nbsp; «2200» — порт ssh; vm_deployment_user: & nbsp; «ocpadmin» — пользователь ssh.
После выполнения всех необходимых переменных мы можем запустить наш скрипт с помощью следующей команды, которая запустит процесс автоматического развертывания «узла:
$ ansible-playbook -i/etc/ansible/hosts ansible-openshift-add-app-node.yml
Обратите внимание, что Red Hat Ansible подключается к узлам с помощью ключей ssh. Я предполагаю, что у пользователя есть правильные ключи для доступа ко всем доступным узлам в облаке.
После успешного выполнения playbook в облаке Microsoft Azure и в OpenShift (после выполнения команды «oc get nodes» в «defaults») вы должны увидеть узел, готовый к запуску приложений/контейнеров.
Снимок экрана, показывающий правильное добавление узла «s1» на платформе OpenShift.
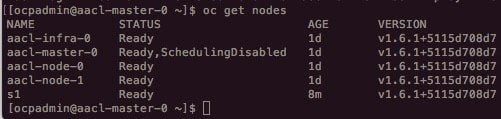 правильное добавление узла «s1» < p> Снимок экрана, показывающий правильную доставку узла «s1» в гибридном облаке.
правильное добавление узла «s1» < p> Снимок экрана, показывающий правильную доставку узла «s1» в гибридном облаке.
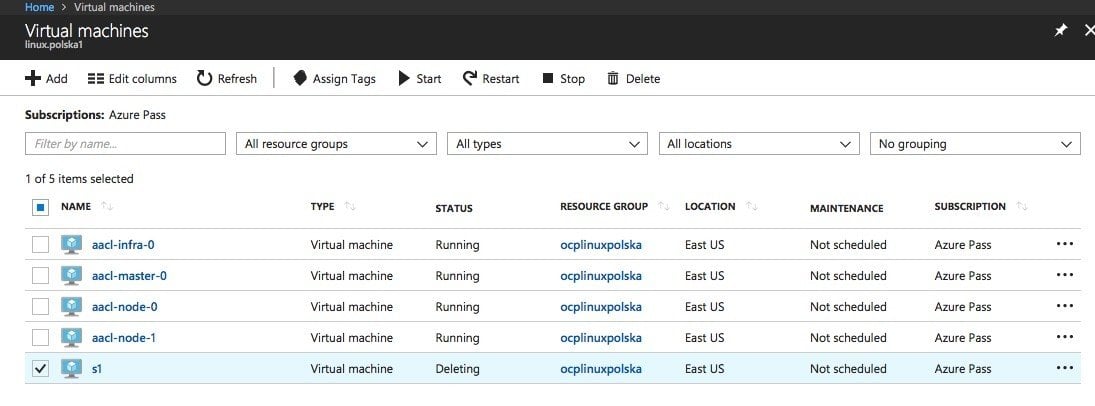 успешная доставка узла «s1» Успешно . Что дальше?
успешная доставка узла «s1» Успешно . Что дальше?
В этой статье я показал, как доставить полнофункциональный узел в инфраструктуру OpenShift с помощью Red Hat Ansible и Microsoft Azure.
Конечно, Ansible как инструмент автоматизации дает нам гораздо больше возможностей. С помощью playbooks вы можете легко автоматизировать процесс масштабирования инфраструктуры в зависимости от различных факторов. Все зависит от информации, которую мы предоставляем инструменту Ansible. Таким образом, метод автоматического масштабирования может снизить затраты на поддержку приложения в гибридном облаке. Такая функциональность была бы невозможна без платформы OpenShift и контейнеризации.
Если вы хотите узнать больше об OpenShift и Ansible в модели гибридного облака, свяжитесь с нами.
Связанные записи :
Новое измерение автоматизации с Red Hat Ansible Automation Platform
Настройка систем Windows с помощью Ansible в MS Azure
Ansible для Splunk более эффективный процесс создания приложений
Интеграция Ansible и Splunk в стратегии автоматизации ИТ
Warta трансформирует ИТ благодаря контейнеризации